Data-Layer Security When the Perimeter Is Gone
Data-layer security binds identity, policy, and encryption to the data object itself, so protection survives lost networks, stolen devices, and the quantum era.


Data-Layer Security: Protecting Regulated Data When the Perimeter Is Gone
By Paul Bockelman, CTO and VP of Product Engineering, Qanapi
Data-layer security is the practice of binding protection to the data object itself, rather than to the network, device, or application around it. For regulated industries it is quickly becoming the only model that holds, because the perimeter those industries were told to defend no longer exists in any reliable form.
The defense environment never had a clean perimeter. Operators share devices. Networks degrade or disappear. Identity rotates mid-mission. Coalition partners join under different rules of engagement, then leave. The perimeter was always a polite fiction in this domain, and now every regulated industry (finance, healthcare, technology, utilities, transportation, telecommunications) is starting to look the same.
Defense requirements are already moving toward the data. Frameworks like CMMC 2.0, NSM-10, and CNSA 2.0 push protection toward the data object and the cryptography itself, not just the network around it. Those requirements break every model that depends on something other than protection at the data level. Perimeter security, without zero trust at the data layer, is attached at best to a system that will eventually be lost, blocked, or compromised.
This is the post-perimeter operational reality, and it changes the security game. Regulated industries can learn from the research, testing, and implementation across the national security apparatus to bring quantum resistance and crypto agility to legacy and modern systems alike.
Your security stack assumes a world that doesn't exist.
Most security architectures are built for a stable enterprise environment. They make sensible assumptions: the network is up, the device is enrolled, the identity is trustworthy, the data is sitting where it was put. In regulated environments, none of these assumptions holds for long.
None of this means the existing layers are wrong. They are necessary. They are simply not sufficient in environments where the operator, the network, and the device can each fail at any time.
What data-layer security actually means
The way out is to stop layering protections around the data and start binding the protection to the data itself.
Picture a sensitive file that does not just sit on a server waiting to be retrieved, but carries its own policy. The file knows who is authorized to see it, under what conditions, and for how long. Even if it lands on an adversary's laptop, on a compromised cloud, or in a partner's inbox, it stays unreadable because the conditions are baked into the object. The protection moves with the data, not with the network around it.
That is data-layer security, and it rests on the triad at the core of Qanapi's patent portfolio (one issued, three pending): identity, policy, and encryption fused at the level of the data object. None of the three is new. What is new is binding them together so tightly that none can be subverted without the others.
In practice, this changes what happens in the moments that matter most:
- When the network goes down, the data still enforces its own policy. There is no central gateway the user has to reach.
- When an identity is rotated, revoked, or compromised, the policy can change immediately, without re-encrypting the data.
- When a device is shared or in the field, only the right user-and-policy combination can decrypt. A second user on the same hardware sees nothing.
- When international partners come and go, each gets exactly the view of the same dataset that their authorization permits, with no duplicates and no separate environments.
Encryption at the data level brings this reliability without slowing operations or collaboration. You can see it inside a real document with Qanapi Live Redaction for Google Docs, which keeps a classified passage encrypted to an uncleared collaborator while a cleared one reads it in the same file.
What data-layer security looks like in practice
The model becomes concrete in five problems that regulated organizations across defense, finance, healthcare, telecommunications, energy, and technology are already running into.
Compliance is becoming an architectural test
Compliance audits across regulated industries are no longer checking for controls at the perimeter. They are looking at how sensitive data actually moves: between contractors and primes, between care teams and billing systems, between trading desks and clearing counterparties, between network operators and third-party vendors. The architectural question (whether the controls live with the data or with the environment around it) is now the one that decides whether the program passes.
When the data carries its own policy, enforcement is no longer a perimeter problem. A CUI marker in a defense contractor's workflow is enforced at the file. PHI in a health system's cloud is enforced at the record. Nonpublic financial information in a capital markets platform is enforced at the document. The same architectural approach can satisfy CMMC 2.0, the HIPAA Security Rule, the GLBA Safeguards Rule, NERC CIP, and CPNI obligations at once, because the controls live with the data rather than the infrastructure around it.
Multi-party data sharing without the reconciliation tax
Regulated organizations share sensitive data across boundaries constantly. Defense contractors share technical data with coalition partners and foreign military sales recipients. Health systems share records across care networks, payers, and research consortia. Financial institutions share transaction data with clearing counterparties, regulators, and syndicate partners. The traditional answer, duplicate the data, redact it, and distribute it through separate environments, produces multiple versions, drift between them, and a reconciliation burden that grows with every party added.
A data-level approach turns this into a configuration choice. One dataset can expose different views to different parties based on their authorization, without duplication and without separate environments. Adding or removing a party adjusts access. It does not trigger a re-issue of the underlying data.
Data that survives endpoint compromise
Every organization with field operations, distributed infrastructure, or third-party device access eventually faces the same problem: hardware moves outside the perimeter and does not come back clean. A forward-deployed sensor is captured. A clinician's laptop is stolen from a car. A field technician's tablet at a remote substation is compromised. The assumption that data on these endpoints can be remotely recalled or reliably wiped breaks the moment the device is unreachable.
Data-layer security inverts this. Even if the hardware is compromised, the data refuses to decrypt outside the policy bound to it. The stolen device yields cryptographic noise, not files, and the compromised endpoint can be revoked without re-keying everyone else.
Operational timelines that don't wait on key management
Operational tempo is often constrained by infrastructure. In defense, key management delays mission planning when distribution systems cannot keep pace. In healthcare, clinicians wait on access provisioning. In financial services, trading desks sit idle while IT provisions counterparty access. When keys flow from a central distribution point, key management becomes a gating item, and when the timeline changes, key management lags.
Data-level architecture pre-stages access policies as part of operational planning rather than after it. Keys become available to the right systems before they are needed, and they expire, rotate, or revoke automatically as the operation moves through its phases. Key management stops being a bottleneck and becomes a planning input.
AI workflows where you control what the model sees
Contracts with AI vendors are remediation tools, not controls. Once sensitive data enters an AI workflow for inference, training, or classification, what the model sees is determined by the vendor's plumbing. A health system running clinical notes through a diagnostic model faces the same exposure as a bank running customer data through fraud detection. Vendor logs, training pipelines, and downstream subprocessors all have access by default unless something at the data level prevents it.
Data-layer security keeps the model boundary under the customer's control. The data enters the workflow already protected by its own policy, so the model sees what the policy permits and nothing more. "What did the model see, and under what authorization?" becomes an answerable question rather than an inferred one.
These are not five problems with five solutions. They are five expressions of one problem: protection bound to infrastructure cannot survive the environments regulated organizations actually operate in. Encrypting at the data layer solves all five.
Why post-quantum makes data-layer security a today problem
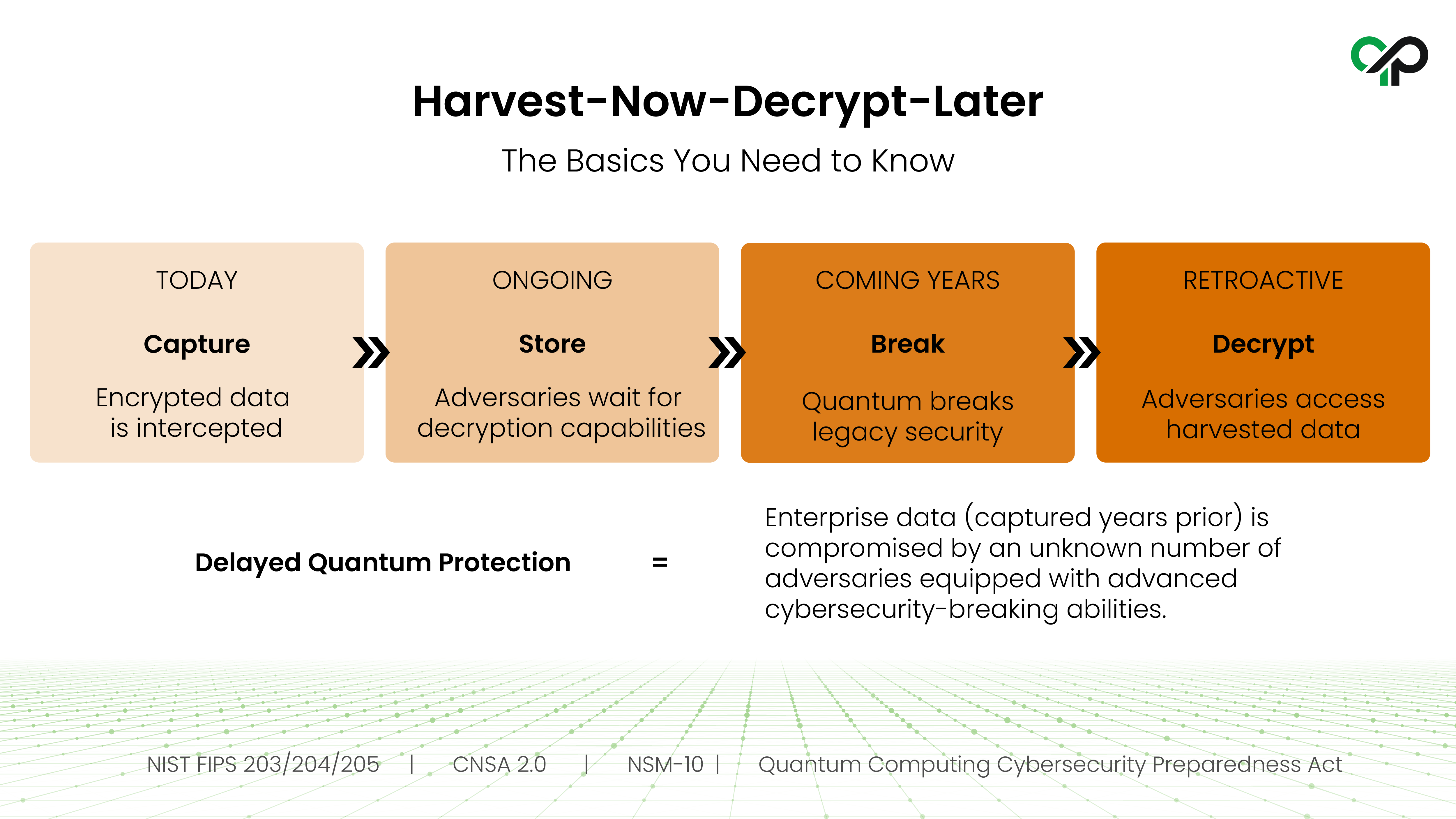
Harvest-now-decrypt-later is the strategy adversaries are already running: intercept encrypted communications and stored data today, archive them, and wait until quantum computers can decrypt them. The question is whether the data still matters when that day comes.
For regulated organizations, the answer is almost always yes. Defense contractors handle CUI with confidentiality horizons measured in decades. Patient records, financial transaction histories, energy infrastructure schematics, and strategic IP carry the same long tail. Mosca's inequality formalizes the exposure: if the time until quantum computers can break current cryptography, plus your migration time, is less than your data's confidentiality horizon, you are already exposed. And the clock is moving. In the Global Risk Institute's annual expert survey, respondents put the probability of a cryptographically relevant quantum computer within ten years at 28 to 49 percent, and noted the timeline has accelerated from prior years. For most regulated organizations, the migration window has already opened.
The standards exist. NIST finalized the post-quantum cryptography standards in August 2024 as FIPS 203, 204, and 205. Defense agencies face hard deadlines through CNSA 2.0, NSM-10, and DFARS flow-down, and financial, healthcare, energy, and telecommunications regulators are converging on the same NIST baseline. In June 2026, the White House executive order on quantum innovation named the migration to post-quantum cryptography a national security question, accelerating the policy timeline that regulated industries will inherit. The question is no longer whether to migrate. It is whether migration can happen without re-engineering every system above the cryptographic layer.
The answer is crypto agility at the data level. When identity, policy, and encryption are fused at the data object rather than embedded in perimeter infrastructure, the algorithms can change without changing how data is accessed, shared, or governed. The same property that lets a defense contractor satisfy CMMC 2.0, ITAR, and CNSA 2.0 at once is what makes quantum migration tractable for every regulated industry. Compliance, multi-party sharing, endpoint resilience, operational agility, AI governance, and post-quantum readiness are not separate problems. They are the same architectural decision, made once, at the data layer.
See it work
Data-layer security is easiest to understand inside a document you already use. Start a 30-day free trial of Qanapi Live Redaction and watch a sensitive paragraph stay encrypted to an uncleared collaborator in the same Google Doc.
Related reading: Data-Layer Zero Trust 101 · Overcoming QKD Limitations with DKMS

About Qanapi
Qanapi is a leading innovator in data security and governance. Our encryption API is built for speed and security, so any team can get Zero Trust data protection within minutes. Try it out for free by creating your first project today.


